SAX(Symbolic Aggregate Approximation ):时间序列的符号化表示(附Python3代码,包括距离计算) |
您所在的位置:网站首页 › 代码版权 近似度 › SAX(Symbolic Aggregate Approximation ):时间序列的符号化表示(附Python3代码,包括距离计算) |
SAX(Symbolic Aggregate Approximation ):时间序列的符号化表示(附Python3代码,包括距离计算)
|
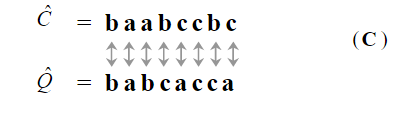
SAX全称 Symbolic Aggregate Approximation, 中文意思是符号近似聚合,简单的说是一种把时间序列进行符号化表示的方法。 SAX的基本步骤如下: (1)将原始时间序列规格化,转换成均值为0,标准差为1 的的序列,原论文中解释的原因如下: (2)通过PAA(Piecewise Aggregate Approximation)进行降维,将长为 n 的原始时间序列 简单的说,PAA就是先把原始序列分成等长的 w 段子序列,然后用每段子序列的均值来代替这段子序列。 PAA降维的公式如下: 转换后的图如下: (3)符号化表示。先选定字母集的大小α, (就是你想用多少个字母来表示整个时间序列,比如选三个字母‘a’, 'b', 'c',则α=3) 然后在下面的表格中查找区间的分裂点 符号化之后的图: 这样原始的时间序列就离散化为字符串:baabccbc 符号化后的时间序列间的距离计算: 给定两个长度都为 n 时间序列 Q 和 C,则序列Q和序列C之间的欧式距离可以用下面计算: 两个原始时间序列的距离: 当时间序列 Q 和 C 经过PAA降维之后,变成
此时计算的距离是: 经过符号化之后,时间序列 Q 和 C 变成 此时计算的距离为:
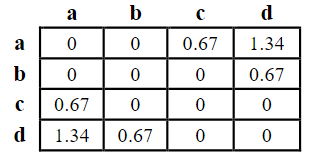
公式中的dist()函数可以从距离表中查到,比如我们选的字母集的大小为4的时候距离表如下: 此时 dist(a, b)=0, dist(a, c)=0.67 注意:不同的字母集大小的距离表不同。 距离表中每个单元格的值可以由一下公式计算: 公式中的
代码如下 import numpy as np import math class SAX_trans: def __init__(self, ts, w, alpha): self.ts = ts self.w = w self.alpha = alpha self.aOffset = ord('a') #字符的起始位置,从a开始 self.breakpoints = {'3' : [-0.43, 0.43], '4' : [-0.67, 0, 0.67], '5' : [-0.84, -0.25, 0.25, 0.84], '6' : [-0.97, -0.43, 0, 0.43, 0.97], '7' : [-1.07, -0.57, -0.18, 0.18, 0.57, 1.07], '8' : [-1.15, -0.67, -0.32, 0, 0.32, 0.67, 1.15], } self.beta = self.breakpoints[str(self.alpha)] def normalize(self): # 正则化 X = np.asanyarray(self.ts) return (X - np.nanmean(X)) / np.nanstd(X) def paa_trans(self): #转换成paa tsn = self.normalize() # 类内函数调用:法1:加self:self.normalize() 法2:加类名:SAX_trans.normalize(self) paa_ts = [] n = len(tsn) xk = math.ceil( n / self.w ) #math.ceil()上取整,int()下取整 for i in range(0,n,xk): temp_ts = tsn[i:i+xk] paa_ts.append(np.mean(temp_ts)) i = i + xk return paa_ts def to_sax(self): #转换成sax的字符串表示 tsn = self.paa_trans() len_tsn = len(tsn) len_beta = len(self.beta) strx = '' for i in range(len_tsn): letter_found = False for j in range(len_beta): if np.isnan(tsn[i]): strx += '-' letter_found = True break if tsn[i] < self.beta[j]: strx += chr(self.aOffset +j) letter_found = True break if not letter_found: strx += chr(self.aOffset + len_beta) return strx def compare_Dict(self): # 生成距离表 num_rep = range(self.alpha) #存放下标 letters = [chr(x + self.aOffset) for x in num_rep] #根据alpha,确定字母的范围 compareDict = {} len_letters = len(letters) for i in range(len_letters): for j in range(len_letters): if np.abs(num_rep[i] - num_rep[j]) |
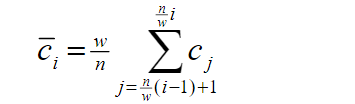



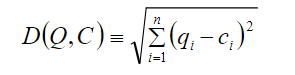

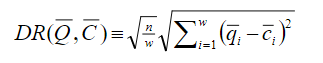

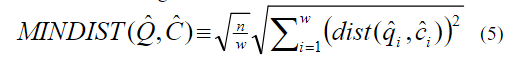
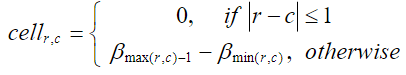
【本文地址】
今日新闻 |
推荐新闻 |